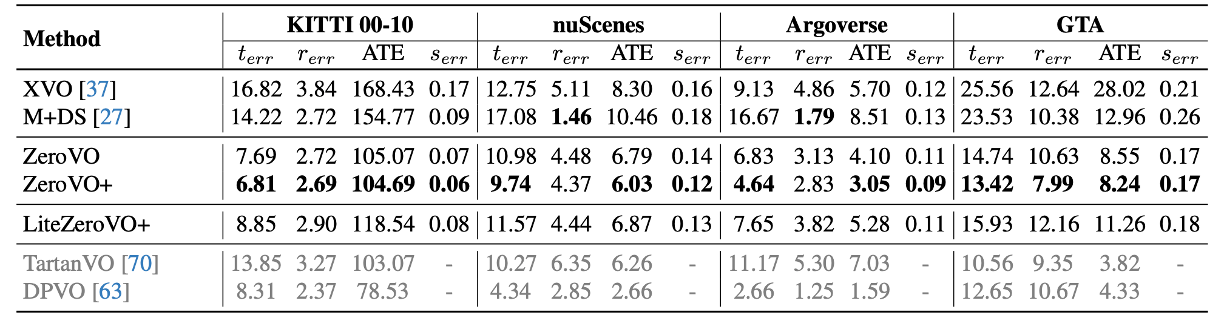
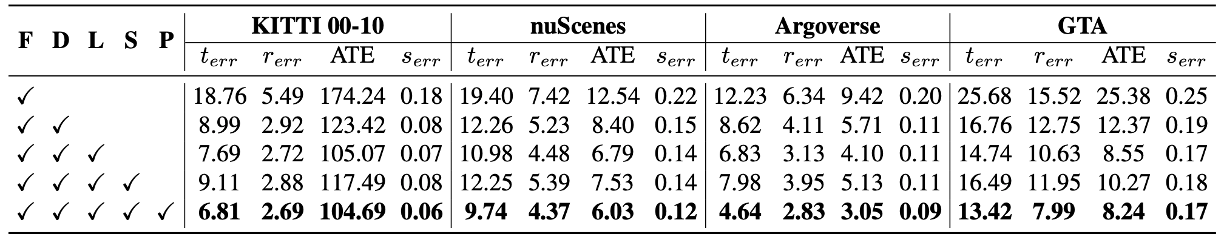
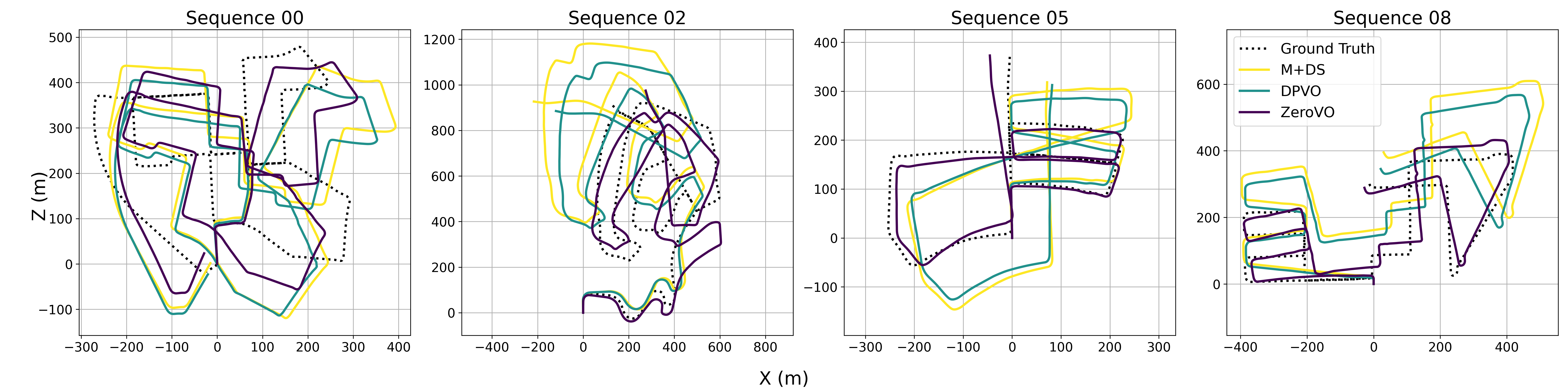
Method
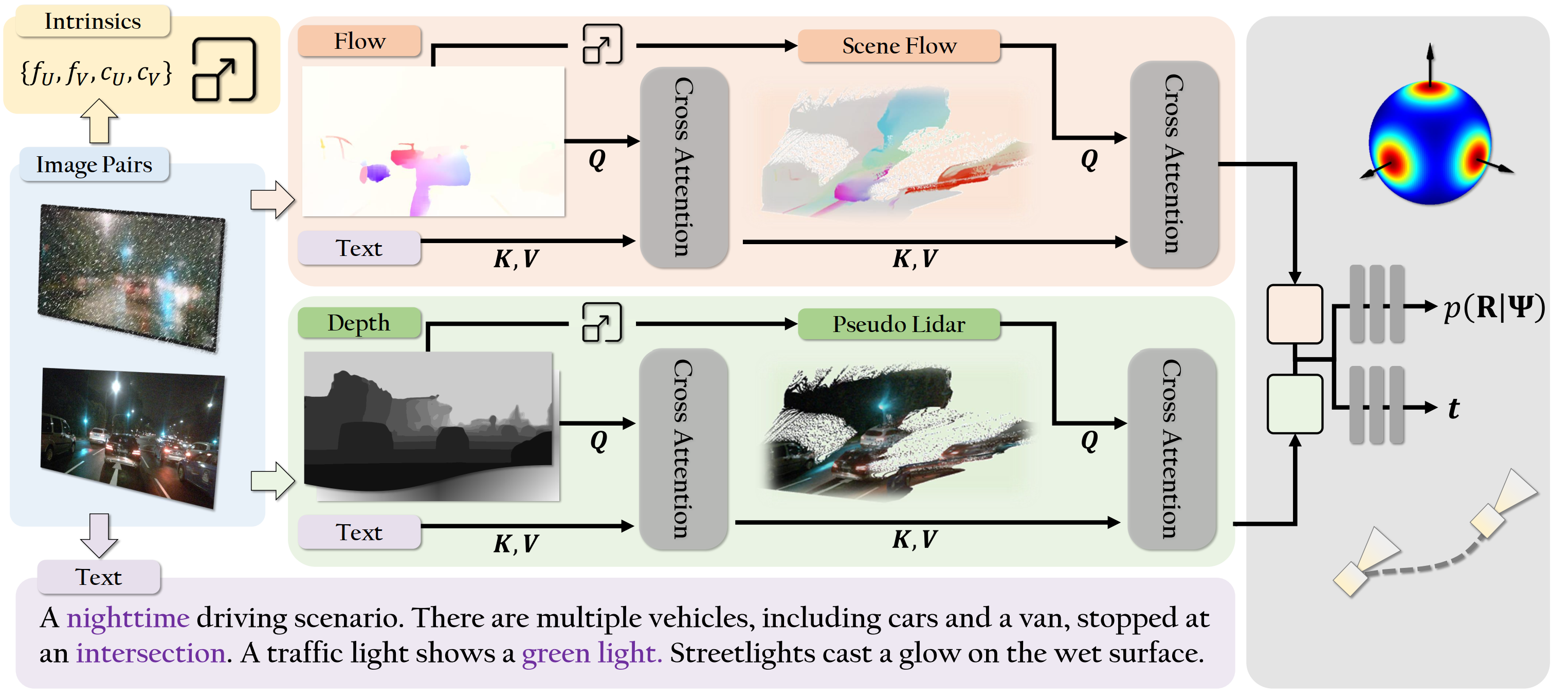
Our method facilitates generalization via minimal and versatile image-based priors, integrated throughout our model structure. Given a pair of input images, our model computes a rich multimodal embedding through a transformer-based fusion module. The embedding is then passed to a two-branch decoder MLP that outputs realworld translation and rotation. Our architecture leverages cross-attention to fuse complementary cues, including flow, depth, camera intrinsics, and language-based features in a geometry-aware manner. The language prior is first used to refine both the depth map and 2D flow estimates. The refined depth is then unprojected into 3D (using estimated parameters) to compute scene flow, which is further enhanced and fused with additional features before decoding. By embedding geometric reasoning and multimodal priors directly into the network structure, our model achieves strong zero-shot generalization across diverse and challenging settings.